Machine learning, a branch of artificial intelligence, concerns the construction and study of systems that can learn from data. With a deluge of machine learning sources both online and offline, a newcomer in this field would simply get stranded due to indecisiveneww. This post is for all Machine Learning Enthusiasts who are not able to find a way to understand Machine Learning (ML).
This tutorial doesn’t require you to have a good deal of understanding of optimizations, linear algebra or probability. It is about learning basic concepts of Machine Learning and coding it. I would be using a python library scikit-learn for various ML applications.
Let’s start with a very simple Machine Learning algorithm Linear Regression.
Linear Regression
Linear Regression is an approach to the model the relationship between a scalar dependent variable y and one or more indenpendent variable X.
n = number of samples m = number of features
A linear regression model assumes that the relationship between the dependent variable $y_i$ and independent variable $X_i$.
a0, a1, …. , am are some constants.
Linear Regression with One Variable (Univariate)
First we start with modelling a hypothesis $h_\theta(X)$.
The objective of linear regression is to correctly estimate the values of and such that approximates to . But how to do that?. For this we define a cost function or error function as:
Linear Regression models are often fitted using least squares approach i.e. by minimizing squared error function (or by minimizing a penalized version of the squares error function). For minimizing the error function we use the Gradient Descent Algorithm. This method is based on the observation that if a function is defined and differentiable in the neighborhood of a point , then decreases fastest if one goes from in the direction of negative gradient of at . So, we can find the minima by updating the value of as:
Where is the step size.
Using the above concept, we can find the values of and as:
Here is called as the learning rate.
Replacing the values of as
We can have a general formula for finding optimal value for any as:
Phew!!!. A lot of mathematics, right?. But where is the code?.
Let’s get our hands on some coding. For this tutorial I would be going to use scikit-learn for machine learning and matplotlib for plotting.
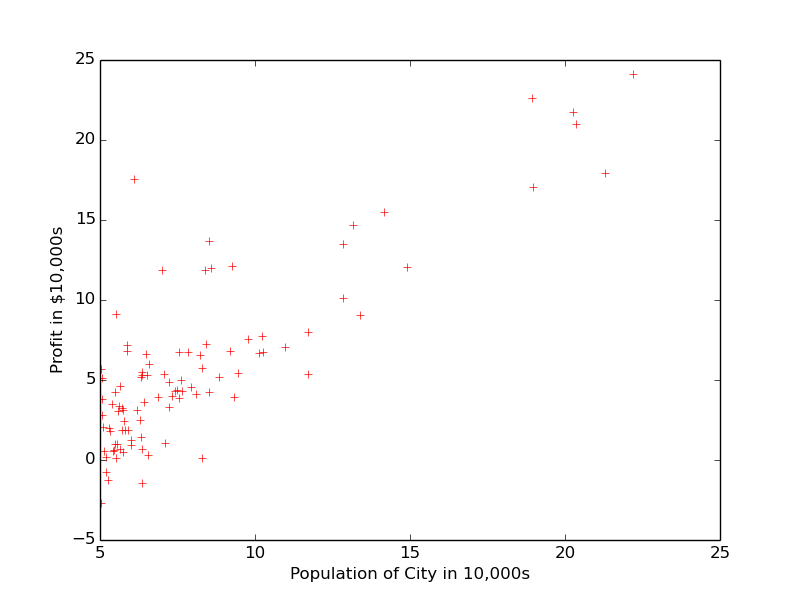
Suppose, for a hypothetical city FooCity, population in 10,000s and profit in $10,000 are available. We want to predict price of a house of particular size.
load_data
12345678910111213141516171819202122232425
importnumpyasnpimportmatplotlib.pyplotaspltinput_file=open('example1.txt')lines=input_file.readlines()X=[map(float,line.strip().split(','))[0]forlineinlines]#X : size of houseX=np.array(X)#converting X from a list to arrayX=X.reshape(X.shape[0],1)#reshaping the X from size(97, ) to (97, 1)y=[map(float,line.strip().split(','))[1]forlineinlines]#y : price of housey=np.array(y)#converting y from a list to arrayy=y.reshape(y.shape[0],1)#reshaping the y from size(97, ) to (97, 1)plt.plot(X,y,'r+',label='Input Data')#plotting house size vs house priceplt.ylabel('Profit in $10,000s')plt.xlabel('Population of City in 10,000s')plt.show()
It is visible from the plot that Population and Profit are varying linearly, so we can apply linear regression and predict profit for a given population.
For performing Linear Regression we have to use LinearRegression class available in sklearn.linear_model.
linear_regression
123456
fromsklearn.linear_modelimportLinearRegressionclf=LinearRegression()clf.fit(X,y)#linear regression using scikit-learn is very simple.#just call the fit method with X, y
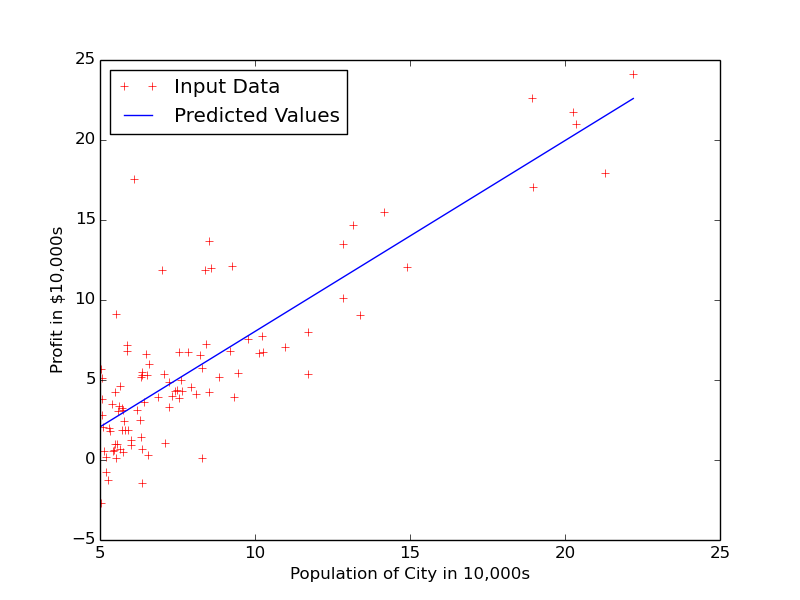
We can now predict the value of Profit for any Population(such as 15.12*10000) as clf.predict(15.12).
plot
123456
x_=np.linspace(np.min(X),np.max(X),100).reshape(100,1)#x : array with 100 equally spaced elements starting with #min value of X upto max value of Xy_=clf.predict(x_)plt.plot(x_,y_,'b',label='Predicted values')plt.legend(loc='best')
Next, we would be going for Multivariate Linear Regression.
A Web crawler is an Internet bot that systematically browses the World Wide Web, typically for the purpose of Web indexing.
This tutorial is about building your own web crawler - not the one that can scan the whole internet(like Google), but one that is able to extract all the links from a given webpage. For this tutorial, I would be extracting information from IMDb.
IMDb is an online database of information related to films, television programs and video games. I woulb be going to parse IMDb Top 250 and IMDb: Years and extract information about the movies ratings, year of release, start casts, directors, etc.
First, let’s write a simple program (hard-code) to parse IMDb Top 250.
Going through the code in details. For this simple parser I have used parse from lxml.html.
tree = parse('http://www.imdb.com/chart/top') parses the url and returns a tree.
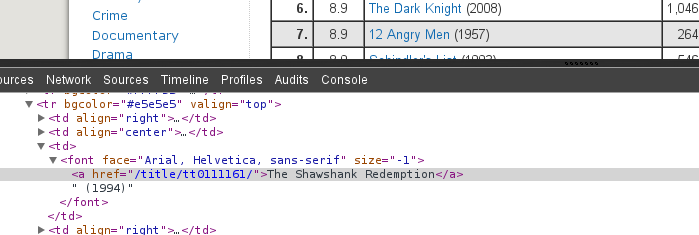
Before going on the next line, lets discuss about XPath. XPath, the XML Path Language, is a query language for selecting nodes from an XML document. XPath Tutorial is a very good tutorial for XPath by w3cschools.com. In the XPath, ‘//*[@id=“main”]/table[2]/tr/td[3]/font/a’.
// : Selects nodes in the document from the current node
that match the selection no matter where they are.
/ : Selects from the root node
/tr/td[3]: Selects the third td element that is the child of the tr element.
To get the XPath of an element, you can use Google Chrome. Click on Inspect Element.
Then select Copy XPath. This would give you the XPath to be used. Remember to remove <tbody> element from the XPath. and also remove [] from tr as you want to scrape the whole movies list.
Similarly you can find the XPath for movies_rating also.
Then in
get_movie_data
123456789
defget_movie_data(iterator):""" Returns movie_name, year_of_release as movies_data[element].itertext() would return an iterator containing these two elements"""movie_data=(iterator.next(),iterator.next())returnmovie_datamov_dict={get_movie_data(movies_data[i].itertext())[0]:[int(get_movie_data(movies_data[i].itertext())[1].strip(' ()/I')),movies_rating[i]]foriinrange(len(movies_data))}
movie_dict is built containing the dictionary with
Let’s go a step further. After writing a simple (but hard-coded) parser, I am going to write a more generic (yet simple) parser. For this, I have take some concepts from scrapy(imitation is the best form of flattery) and have used lxml for scrapping.
I would be scraping the IMDb: Years page. This page contains the links for pages containing the links for Most Popular Titles Released in that year. In the next blog, I would be using the data scraped (a dictionary {year: [name, rating, genres, director, actors]} for analysing trends in Movies.
importurllib2importrefromlxml.htmlimportparseclassCrawler():def__init__(self,settings):""" settings should be a dictionary containing domain: start_url: EXAMPLE settings = {'domain': 'http://www.imdb.com', 'start_url': '/year'} """self.settings=settingsself.rules={self.settings['start_url']:'parse'}self.parsed_urls=[]self.url_list=[]def_get_all_urls(self,response):""" _get_all_urls returns all the urls in the page """tree=parse(response)url_list=tree.findall('//a')url_list=[url.attrib['href']ifurl.attrib['href'].startswith('http://')elseurllib2.urlparse.urljoin(self.settings['domain'],url.attrib['href'])forurlinurl_list]returnurl_listdefset_rules(self,rules):""" set_rules set the rules for crawling rules are dictionary in the form {url_pattern: parsing_function} EXAMPLE >>> settings = {'domain': 'http://www.imdb.com', 'start_url': '/year'} >>> imdb_crawler = Crawler(settings) >>> imdb_crawler.set_rules({'/year/\d+': 'year_parser', ... '/title/\w+': 'movie_parser'}) """self.rules=rulesdef_get_crawl_function(self,url):""" _get_crawl_function returns the crawl function to be used for given url pattern """forpatterninself.rules.keys():ifre.search(pattern,url):returnself.rules[pattern]defparse(self,response):""" parse is the default parser to be called """passdefstart_crawl(self):""" start_crawl is the method that starts calling EXAMPLE >>> foo_crawler = Crawler() >>> foo_crawler.start_crawl() """response=urllib2.urlopen(urllib2.urlparse.urljoin(self.settings['domain'],self.settings['start_url']))self.url_list=self._get_all_urls(response)forurlinself.url_list:ifurlnotinself.parsed_urls:crawl_function=self._get_crawl_function(url)ifcrawl_function:getattr(self,crawl_function)(urllib2.urlopen(url))self.parsed_urls.append(url)
Crawler object have to be initailized with a dictionary settings {‘domain’: domain_of_\page, ‘start_url’: start_url_page} The Crawler class has attribute url_list that contains all the urls to be parsed and parsed_urls is a list of all the parsed urls.
_get_all_urls
123456789101112
def_get_all_urls(self,response):""" _get_all_urls returns all the urls in the page """tree=parse(response)url_list=tree.findall('//a')url_list=[url.attrib['href']ifurl.attrib['href'].startswith('http://')elseurllib2.urlparse.urljoin(self.settings['domain'],url.attrib['href'])forurlinurl_list]returnurl_list
_get_all_urls retrieves all the urls present in the web page. tree.findall(‘//a’) would return all the //a tags present in the web page. If the url starts with http:// then it would append it as usual; but if the url is a relative url, it would append the final url formed by joining the url with the domain
parse(response) is the default parser of the Crawler. More sophisticated or complex parsers can be written for different urls using set_rule. For example:
set_rule
123456
settings={'domain':'http://www.imdb.com','start_url':'/year'}imdb_crawler=Crawler(settings)# year_parser is parser for scraping year pages# movie_parser is parser for scraping movie pagesimdb_crawler.set_rules({'/year/\d+':'year_parser','/title/\w+':'movie_parser'})
All the parser should have be an input parameter response. Discussed below in details.
start_crawl
123456789101112131415161718
defstart_crawl(self):""" start_crawl is the method that starts calling EXAMPLE >>> foo_crawler = Crawler() >>> foo_crawler.start_crawl() """response=urllib2.urlopen(urllib2.urlparse.urljoin(self.settings['domain'],self.settings['start_url']))self.url_list=self._get_all_urls(response)forurlinself.url_list:ifurlnotinself.parsed_urls:crawl_function=self._get_crawl_function(url)ifcrawl_function:getattr(self,crawl_function)(urllib2.urlopen(url))self.parsed_urls.append(url)
start_crawl is the main function that initiates crawling. First, it tries to get all the urls present in the start_page. It then searches the parser to be called for that particular url using _get_crawl_function.
12345678
def_get_crawl_function(self,url):""" _get_crawl_function returns the crawl function to be used for given url pattern """forpatterninself.rules.keys():ifre.search(pattern,url):returnself.rules[pattern]
The particular parser is then called according to rules set above. Finally the url is appended into parsed_urls list.
Using the above Crawler, I have implemented IMDbCrawler.
movie_parser would crawl the movie web page and add the details of the movies such as its ratings, director, genres in the dictionary movie_final_dict. There are some movies where data (rating, actors, etc.) is missing, so I have included try and except statements.
imdb_crawler is an instance of IMDbCrawler. It has been instantiated with the domain http://www.imdb.com and start_url /year. Then the rules are set for different urls. It would call year_parser for all the webpages in the format of http://www.imdb.com/year/1992 and movie_parser for webpages in the format of http://www.imdb.com/title/tt0477348/.